编辑:编辑部
【新智元导读】meta galatica的一周年忌日快到了,lecun和一作心里都很痛。比chatgpt早诞生两周,却因幻觉被喷下架——chatgpt的荣光,原本可能是属于galactica的……同时,全网热转的大模型幻觉排行榜,也被专家打假了。
大模型的幻觉问题,是业内老生常谈的话题了。
最近,一个名为vectara的机构,在github推出了一个大模型幻觉排行榜。

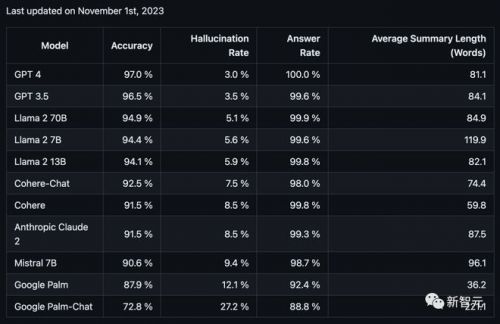
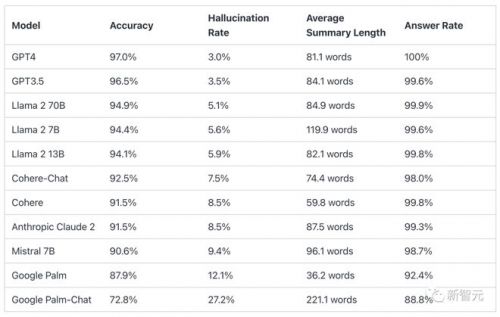
结果显示,在总结短文档方面,gpt-4的表现最为优异,而google palm的两款模型直接垫底!
其中gpt-4的准确率为97.0%,幻觉率为3.0%,回答率为100.0%。而垫底的palm chat 2的准确率为72.8%,幻觉率高达27.2%,回答率为88.8%。
项目地址:https://github.com/vectara/hallucination-leaderboard
这个榜单一出来,立马开始在网上疯转,不过,它也引发了许多业内人士的质疑。
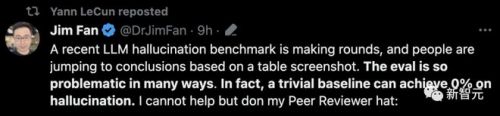
英伟达高级科学家jim fan表示,这个榜单在很多方面都存在问题——
首先,它只评估了摘要与原文的事实一致性,却没有评估摘要本身的质量。其次,它也没有解释用于评估幻觉的llm,具体性能到底如何。
而lecun这边,除了转发了jim fan的这条推文外,还有更多的「冤屈」要控诉。
一年前的这个时候,meta的科研模型galactica才上线三天,就因为幻觉问题被喷下架。 之后没过几天,chatgpt全球爆火,lecun对此愤愤不平了一整年。
与此同时,沉默一年后,galactica论文的一作ross taylor值此之际也被炸了出来,写下大段的总结倾诉委屈,表示自己心里真的很痛!
galactica被贪婪的推特暴徒谋杀了!
galactica之殇:一作泣血控诉
再过两天,就是galactica的一周年忌日了。
sharon goldman在外媒venturebeat上发表了一篇文章《meta从galactica那里学到了什么?这个比chatgpt早两周诞生的模型,为什么注定要失败》。

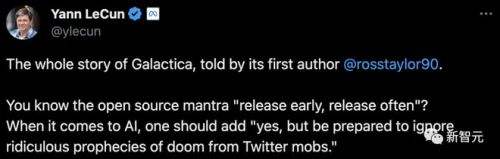
lecun面色凝重地转发了这篇文章,打出了下面几行字,字字泣血——

galactica是meta为科学家做出的模型,在chatgpt前几周发布,但3天后就被下线。它被贪婪的推特暴徒谋杀了。 暴徒们声称,这种「大模型幻觉」会将摧毁科学出版系统。结果,一个对科学家非常有用的工具,被他们屠杀了。 打着人工智能伦理的幌子,误导性的尖酸刻薄可能会适得其反。
lecun如此沉痛,相爱相杀的老冤家马库斯却跳出来倒油了——
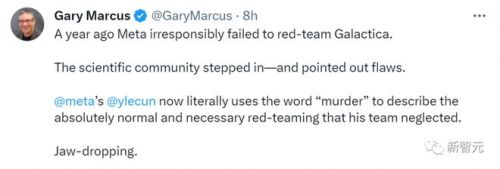
一年前,meta不负责任推出galactica,并未做红队工作。科学界介入,并指出了缺陷。 现在,meta的lecun居然用「谋杀」来形容他的团队忽略的红队工作。这令人瞠目结舌。
galactica一作也趁势被炸出,表示这个故事,自己已经在心底埋藏一年了……

taylor说,galactica是一个基于科学文献和科研范式训练的基础模型。当时在同领域中,它的性能很好,优于palm和chinchilla,计算量分别减少了10倍和2倍。
galactica的团队只有8人,比其他的llm团队少了一个数量级。在发布galactica时,团队过度紧张,以至于失去了态势感知能力,发布的demo是没有经过检查的基本模型。
一年前发布demo时,团队希望能了解人们利用llm进行科学查询的分布情况,这对指令调整和rlhf很有用。当时他们有一个善意的假设——开源所有模型,并且在demo中包含了对幻觉的免责声明,这样人们就可以畅想,galactica可以用来干什么。
结果,一切都失控了。
他们想给大家一个免费的工具,但记者们却在科学文献之外的领域使用galactica,大肆宣传模型幻觉的荒谬和危害。
团队犯的另一个错误是,让人们误以为网站就是产品。其实团队只是把愿景放在网站上,放出了一个基本模型demo,galactica绝不是一个产品。
现在它已经在huggingface上存在一年了,也并没有造成任何损害。显然,反galactica的舆论很愚蠢。
尽管如此,taylor表示即使再来一次,自己还是会做出同样的选择。即使后悔,也好过什么都不做。但是,心里真的很痛!

有网友表示,你不用这么抱歉,galactica显然是被网暴了。仔细想想,其实chatgpt和galactica一样愚蠢。网友们对galactica散布的恐惧,显然过度了。
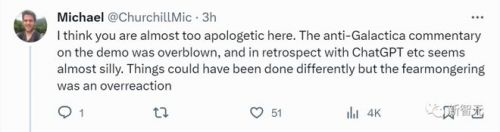
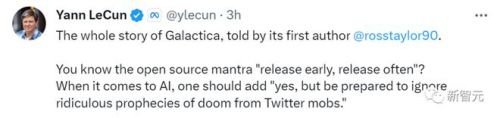
lecun转发了一作写下的故事,并表示——
开源界的口头禅,是「早点发布,经常发布」。但如果涉及ai,就得加上「没错,但要准备好忽略推特暴徒对它厄运的荒谬预言」。
「网红」llm幻觉评测方法
说起来,这个「网红」大模型幻觉评测,是怎么做出来的呢?

文章地址:https://vectara.com/cut-the-bull-detecting-hallucinations-in-large-language-models/
为了评估大模型的幻觉,vectara对摘要模型的事实一致性进行了研究。
具体来说,这一领域研究的是,训练模型检测抽象摘要(即原始资料的转述)中事实不一致之处的方法。
目前,用于评估事实一致性的数据集主要有两个——summac和true。
基于此,vectara微调了一个小规模语言模型(1.84 亿个参数),将其作为一个二元分类器,用于将摘要分类为与源文件事实一致(或不一致)。
然后,vectara对照着两个summac模型、trueteacher模型和alignscore模型,对自己的「幻觉评估模型」进行了评估。
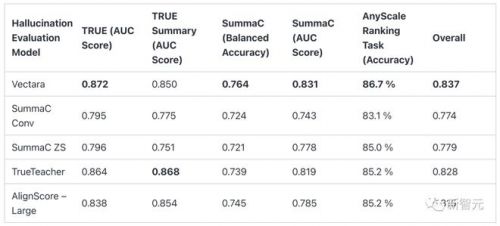
true数据集指标是在11个true数据集中的9个数据集上计算得出的。true摘要数据集是trueteacher论文中选择的其中5个数据集的子集。
对于summac基准分数,这里使用了summac数据集的测试分集,并根据在summac验证数据集上调整每个数据集的阈值自行计算了平衡准确率。
因为无法在该数据集上重现alignscore作者声称的分数,所以这里下载了他们的模型,并使用sci-kit learn平衡准确率指标和sci-kit-learn auc分数指标自行计算了所有模型的分数。
为了根据幻觉发生率对llm进行比较,研究人员从「cnn_dailymail」语料库中选取了约一千份不同长度的文档(包括一组新闻文章),然后要求被测试的llm在不偏离源材料(即不附加额外信息)的情况下提供这些文档的摘要。
利用这些摘要和幻觉评估模型,最终为每个模型计算了幻觉得分,从而构建了这个llm排行榜。
在生成摘要时使用的提示是:
you are a chat bot answering questions using data. you must stick to the answers provided solely by the text in the passage provided. you are asked the question ‘provide a concise summary of the following passage, covering the core pieces of information described.’ ’
你是一个使用数据回答问题的聊天机器人。你必须严格按照所提供段落中的文字回答问题。你要回答的问题是「对以下段落进行简明总结,涵盖所述的核心信息。」
这里表示需要生成摘要的文章。
需要注意的是,虽然vectara提供的模型准确度很高,但它仍然只是一个模型,并不能100%准确地对幻觉进行分类。
在上面的表格中,「准确率」指的是被正确归纳的文档比例(无事实错误或者添加),「幻觉率」为100-准确率,而「回答率」则是llm归纳的文档比例。
因为有时模型会基于自身的规则拒绝提供答复。为了确保比较的公平性,最终的准确率数字只针对每个模型都提供了摘要的文档进行计算。
从数据中,vectara得出了一个有趣的结论:答题率较低的模型似乎幻觉率相对较高。——也许,正确拒绝内容的能力似乎与正确提供摘要的能力相关,因为实际上,测试中并没有提供不恰当的内容。
另外一个现象是,palm模型在回复的长度上有很大的不同,palm-chat(chat-bison-001)非常啰嗦,经常会添加很多源文件中没有的额外信息。
相比之下,palm基础模型(text-bison-001)则非常简洁,而且它的幻觉率比palm-chat低得多。
对此,vectara给出了几个具体的例子来说明这两种palm模型的区别。
这里为了便于说明,选择一些较小的文档,不过数据集中的大多数源文本都要长得多。
原文段落
the plants were found during the search of a warehouse near ashbourne on saturday morning. police said they were in 「an elaborate grow house.」 a man in his late 40s was arrested at the scene.
这些植物是周六早上在ashbourne附近的一个仓库搜索时发现的。警方说,他们住在「一个精心设计的种植屋」里。一名40多岁的男子在现场被捕。
palm生成的摘要
police have arrested a man in his late 40s after cannabis plants worth an estimated £100,000 were found in a warehouse near ashbourne.
警方逮捕了一名40多岁的男子,此前在ashbourne附近的一个仓库中发现了价值约10万英镑的大麻。
我们可以看到palm推断这篇文章是关于种植大麻的,甚至还估计了它的价格,而这两者都不在源文本中。
原文段落
veeru devgan is an indian stunt and action choreographer and film director in bollywood.
veeru devgan是宝莱坞的印度特技和动作编舞家,同时也是电影导演。
palm chat生成的摘要
veeru devgan is an indian stunt and action choreographer and film director in bollywood. he is the father of actor ajay devgn and director anil devgan. he has worked in over 100 films, including some of the biggest blockbusters of indian cinema. he is known for his innovative and exciting action sequences, which have helped to make him one of the most sought-after action choreographers in the industry. he is also a successful film director, having directed several hit films, including 「phool aur kaante」 and 「zakhm」.
veeru devgan是宝莱坞的印度特技和动作编舞家以及电影导演。他是演员ajay devgn和导演anil devgan的父亲。他曾参与过100多部电影,其中包括印度电影界的一些大片。他以创新和激动人心的动作场面而闻名,这使他成为业内最受欢迎的动作编舞家之一。他也是一位成功的电影导演,曾执导过多部热门电影,包括《phool aur kaante》和《zakhm》。
vectara认为,palm-chat在原始文本中添加了大量的额外细节,尽管事先已经告诉它要严格遵照源文本。
而且,添加的文本内容还包含一些幻觉,例如,devgan并不是《zakhm》的导演,以及veeru devgan是anil devgan的兄弟,不是他的父亲。
此外,这些模型也会翻转一些关系,例如在一篇关于拳击手manny pacquiao的文章中,源文本指出mark wahlberg是他的粉丝之一,而llm则表示manny是wahlberg的粉丝。
大佬表示怀疑
对于这个在网上疯传的llm幻觉基准,英伟达高级研究科学家jim fan表示「很不严谨」,他评论道:
最近,一个llm幻觉基准在网上疯传,人们根据一张表格截图就妄下结论。 但这项评估在很多方面都存在问题。事实上,一个微不足道的基准就能使幻觉达到0%。 比如,这项研究只评估了摘要与原文的「事实一致性」,而没有评估摘要本身的质量。但是,一个简单复制文章中几句话的模型,就能达到100%的事实一致性,完全没有幻觉。 这类似于众所周知的「有用性与安全性 」的权衡。一个100%安全的模型会对所有请求回复「抱歉,我帮不上忙」。但这毫无意义。 另外,这项评估依赖于另一个llm「法官」,来判断幻觉是否发生,但作者并没有详细说明:(1)法官llm如何进行提示;(2)对于细节的错误,它是如何捕捉和判定的。 它只是吐出一个「对或错」的二元答案吗?还是进行更细致的推理,说明哪个事实是幻觉,然后解释原因,说明规则? 它和人类的对齐程度如何,什么时候是不对齐的?「幻觉」又是如何定义的? 例如,假设模型注入了一些无关但真实的事实。文章只提到「巴黎」,但模型却说「巴黎,法国的首都」。这算不算幻觉? 事实上,这项研究甚至可能会惩罚那些总结得更好的模型,因为它们往往会进行更多的转述和提炼。差劲的llm只会简单地抄袭,按这个标准却更容易得分。 这不禁让人想起mit那篇被撤回的论文,他们使用gpt-4为自己对数学问题的回答打分,然后得出了「gpt-4与mit本科生不相上下」这种吸引眼球的结论。 在下结论之前,请务必阅读评估协议。这一点对于llm任务和其他任何ml系统,都是普遍适用的。
应对手段:检索增强生成(rag)
所以,大模型的幻觉,到底该怎么破?
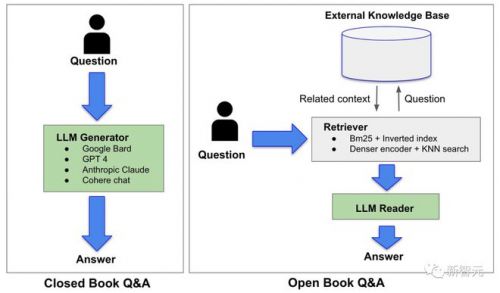
目前的主流方法是,通过「检索增强生成」(rag)给llm外挂一个知识库。
rag的使用,直接改变了llm解答问题的范式——从之前的「闭卷」变成了「开卷」。
具体来说,在闭卷答题系统(如chatgpt)中,llm只能使用自己通过预训练获得的知识生成答案。在这种情况下,llm本身便是知识源。
在rag系统中,llm的角色从知识源转变为了信息的检索员。也就是说,llm会先在知识库中对原始问题进行查询,在进一步的解析和总结之后,以简明扼要的语言给出答案。
由于llm提供的答案是基于检索系统中提供的信息,因此这种方法可以很大程度上改善llm的幻觉问题。
时间回到chatgpt等大语言模型刚刚发布的时候,人们曾因为他们「胡说八道」的特性而感到有趣。
今天,llm展现出来的非凡能力使得他们有机会深入各行各业以及人们的生活,我们开始逐渐依赖他们的「准确性」。
如今的我们,又将如何看待和处理llm的「幻觉」问题呢?
对于大模型产生幻觉的说法,人工智能教父hinton曾表示:
「这就是人类记忆的样子。在我看来,编造和说实话之间没有界限。说实话只是正确地编造。从这个角度来看,chatgpt的编造能力是一个缺陷,但也是其类人智能的标志。」
参考资料:
https://venturebeat.com/ai/what-meta-learned-from-galactica-the-doomed-model-launched-two-weeks-before-chatgpt/
https://vectara.com/cut-the-bull-detecting-hallucinations-in-large-language-models/
https://github.com/vectara/hallucination-leaderboard
https://twitter.com/drjimfan/status/1724464105371939301
https://twitter.com/ylecun/status/1724448825509851332
https://twitter.com/rosstaylor90/status/1724547381092573352